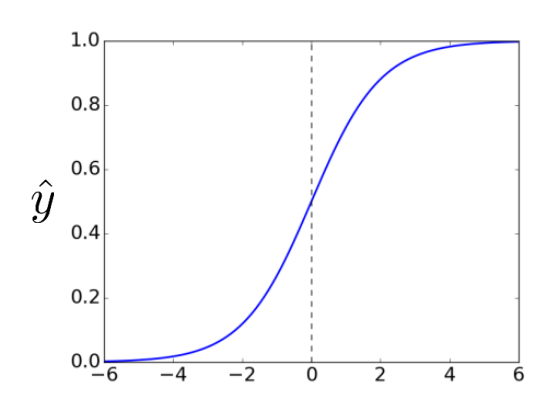
Multiclass Classification은 말 그대로 3개 이상의 class로 나누는 분류문제다. Activation Function으로 Softmax Function이 쓰이는데, 여기서는 왜 Softmax Function이 쓰이는지, 다른 시도와 비교하며 알아보자. 시도1. Multiple Binary Classifiers😶 Multiclass Classification 문제에서 가장 Naive한 방식은, 그냥 Binary Classifier를 여러개 써서 Multiclass로 분류하는 것이다. 여기서 Binary Classifier는 target을 'one-hot vector'로 나타낸다. ((1,0,0,0,...,0)은 1번 class, (0,1,0,0,...,0)은 2번 class.) inp..