😶Learning Rate Scheduling
2023.03.06 - [Data Science/ML | DL] - Optimization: Gradient Descent를 넘어서
Optimization: Gradient Descent를 넘어서
Optimization에 대한 포스팅을 Gradient Descent 를 중점으로 했었다. 2022.08.21 - [Data Science/ML | DL] - Optimization: Random Search부터 Gradient Descent까지 Optimization: Random Search부터 Gradient Descent까지 Optimization이란?😶
dippingtodeepening.tistory.com
Optimizer인 SGD, SGD+Momentum, Adagrad, RMSprop, Adam 모두 Learning Rate를 hyperparameter로 필요로 한다.
고정된 gloabal learning rate를 사용하는 것보다, learning rate를 조건에 맞게 감소시키는 방식이 필요할 수 있다.
이러한 learning rate 조정법을 learning rate scheduling이라고 하며, 그 종류에는 아래와 같은 것들이 있다.
# Linear Decay
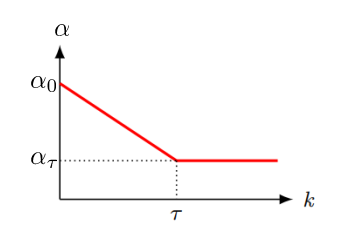
임계지점에 도달하기 이전까지 lr을 선형적으로 감소시키는 방식이다.
# Step Decay
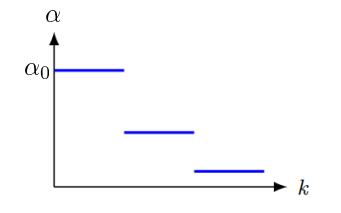
특정 지점에 도달하면 lr을 감소시킨다.
# Exponential Decay
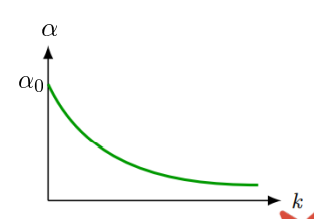
연속적인 exponential 형태로 lr을 감소시킨다.
✔️초기 LR 설정법
제일 처음 learning rate는 어떻게 초기화하는 것이 좋을까.
일반적으로 초기 lr을 설정하는 방식은 아래와 같다.
1. 처음 몇 번(100번 정도)의 iteration을 모니터링해서 가장 performance가 잘 나온 lr을 initial learning rate로 초기화한다.
2. minibatch의 크기를 고려하여 lr을 정한다. (batch size가 클수록 lr을 크게 해도 안정적이다.)
3. 초기화한 lr이 loss explode를 야기하는 것 같다면 lr을 아주 작은 수에서부터 (~최대 5000 iteration까지) linearly increase해본다.
😶Hyperparameter Tuning
✔️파라미터와 하이퍼파라미터의 차이
파라미터는 곧 모델의 형태다. Weight, bias가 파라미터인 것!
training을 하여 파라미터를 계속 업데이트하는 것이 모델 훈련과정이다.
하이퍼파라미터는 우리가 파라미터를 최적화하기 위해 튜닝해야 하는 요소들이다.
lr, #of layers, learning rate, batchsize 등이 하이퍼파라미터이다.
✔️Manual Tuning
하이퍼파라미터 튜닝방식 중 하나다.
말 그대로 여러 하이퍼파라미터 조합을 하나하나 실행해보면서 성능을 비교해 최적 파라미터를 찾는 방식이다.
각 하이퍼파라미터가 어떤 역할을 하는지 이해할 필요가 있는 방식이다.
기본적인 strategy는 최적 하이퍼파라미터를 찾기 위해 cross validation을 하는 것.
# Coarse-to-fine Sampling Scheme
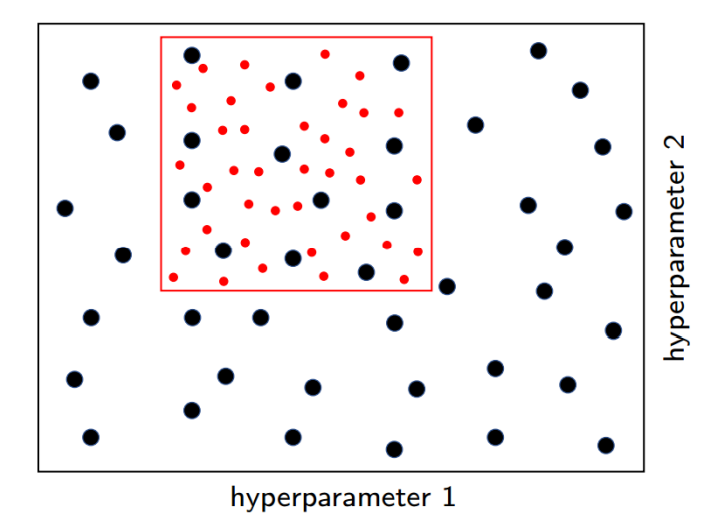
성능이 좋은 하이퍼파라미터 조합이 분포하는 region에 대해서 sampling down하여 다시 시행하면 된다.
# Random Sampling over Grid Search
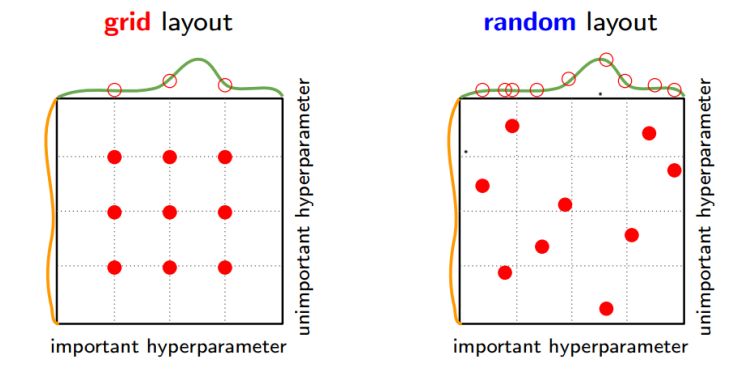
Grid Search 방식은 중요하지 않은 하이퍼파라미터만 바뀌고 중요한 하이퍼파라미터가 고정되어있다면 소용이 없다.
(연산만 많고 성능에는 그렇게 영향이 가지 않을 것이기 때문. 그림 참고)
이 경우 Random Search 방식이 더 exploration 측면에서 유리하다.
특정 하이퍼파라미터가 타 하이퍼파라미터보다 중요한 현상이 반영되기 때문이다.
✔️바람직한 Sampling Distribution
하이퍼파라미터를 샘플링 할 때 적절한 분포에 대한 설명이다.
# Binary/Discrete Hyperparameter
연속적이지 않은 형태의 하이퍼파라미터는 Bernoulli나 Multinoulli 분포에서 샘플링한다.
# Positive Real-Valued Hyperparameter
양의 실수인 연속 하이퍼파라미터는 log-scale의 Uniform Distribution에서 샘플링한다.
그냥 uniform한 분포에서 샘플링하지 않고 log-uniform한 분포에서 샘플링하는 이유는 아래 그림과 같다.
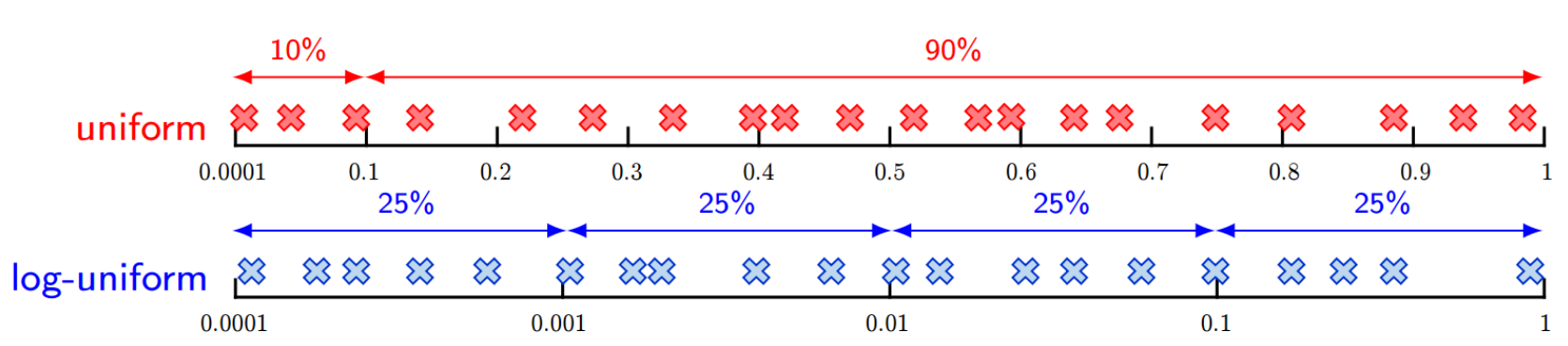
우리가 집중적으로 보길 원하는 하이퍼파라미터 구간기 0.0001에서 0.1이라고 하자.
위의 uniform distribution처럼 샘플링할 경우 원하는 범위의 샘플이 충분히 뽑히지 않는다.
반면 log-uniform distribution의 경우 해당 구간에 대한 성능을 충분히 확인할 수 있다.
✔️하이퍼파라미터 선정 매뉴얼
1. Initial Loss 확인
weight decay를 끈다. 초기설정단계에서의 loss를 확인하는 과정이다.
2. Overfitting a small sample
작은 sample에 대해서 100% accuracy가 될 때까지 training한다.
'학습'을 할 수 있는지 여부를 확인하는 과정이다.
학습시켰을 때 loss의 경향에 따라 학습이 잘 되고 있는지 진단할 수 있다.
* loss가 줄어들지 않을 때 → underfitting이 일어나고 있는 것이다. (too low learning rate, bad initialization)
* loss가 exploding할 때 → learning rate가 너무 높은 것이다. (also bad initialization)
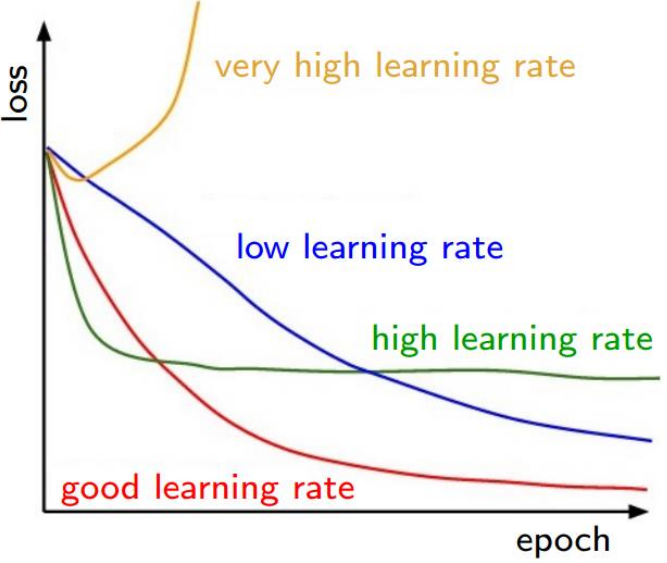
3. Loss를 감소시키는 Learning Rate 찾기
weight decay를 켜고 loss가 우하향 curve를 그리도록 만드는 learning rate를 찾는다.
4. Coarse Grid, Train for 1~5 epochs
3번에서 유력한 lr과 weight decay를 찾아 1~5 epoch만큼만 훈련시켜본다.
5. Refine Grid, Train Longer
4번에서 best model을 선정한다.
선정한 모델을 lr scheduling없이 좀 더 오랜 epoch동안 학습시킨다.
6. Monitor Performance Curve
학습에 이상이 있는지 성능곡선을 통해 확인한다.
필요에 따라 이상이 있다면 5번으로 돌아간다.
😶Performance Curve Monitoring
위에서 설명한 하이퍼파라미터 선정 매뉴얼에서 6번에 해당하는 내용이다.
여러 Performance Curve의 형태를 살펴보고 각각이 어떤 상황에 해당하는지 보자.
✔️ Training Accuracy Curve를 통한 Underfitting / Overfitting 확인
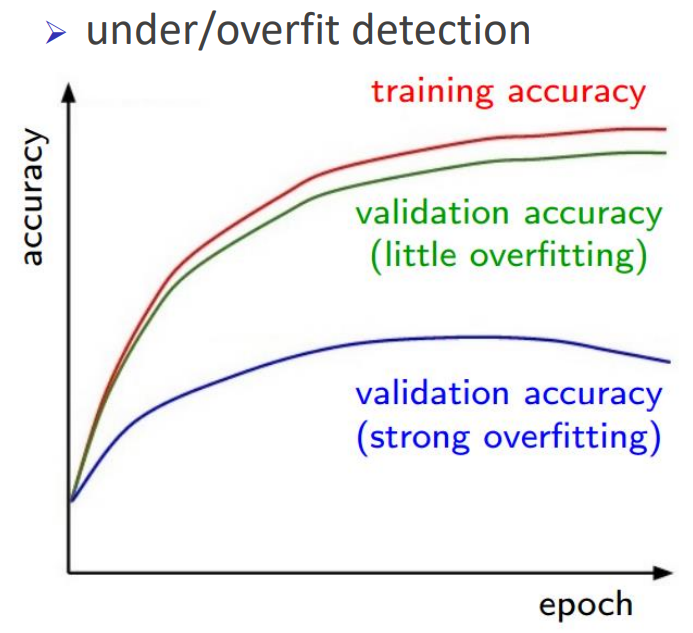
Training Accuracy가 예쁜 곡선을 그리며 우상향해야 학습이 진행되고 있는 것.
✔️ Loss 감소패턴
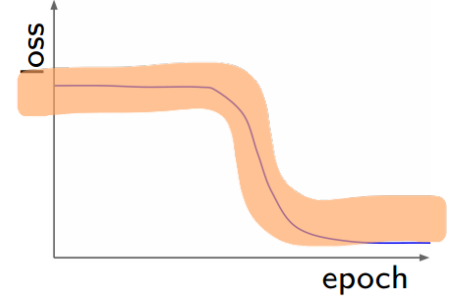
Learning Rate의 Bad Initialization case이다.
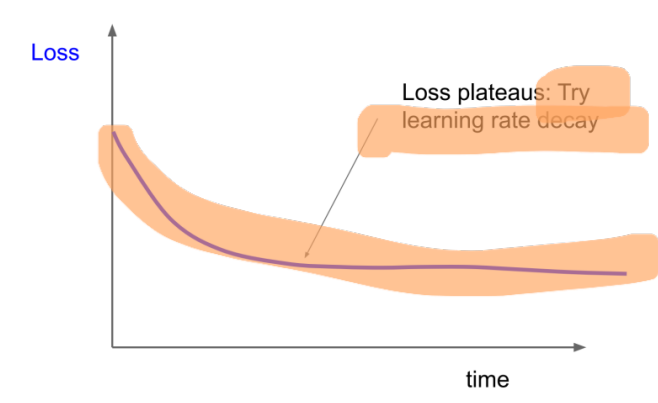
Loss가 감소하지 않고 수렴하는 현상이 일어나고 있음을 확인할 수 있다.
이 때는 Learning Rate를 줄여가야 한다.
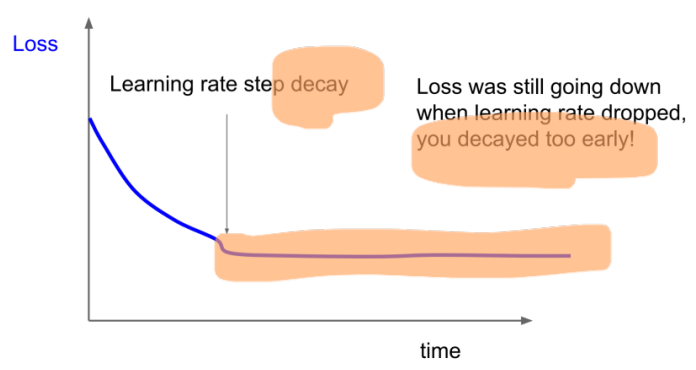
learning rate decay를 너무 일찍 진행했을 때 발생하는 현상이다.
loss가 감소하고 있었는데 learning rate를 줄여버려서 더 이상 loss가 줄어들고 있지 않다.
✔️ Training Acc, Testing Acc 패턴
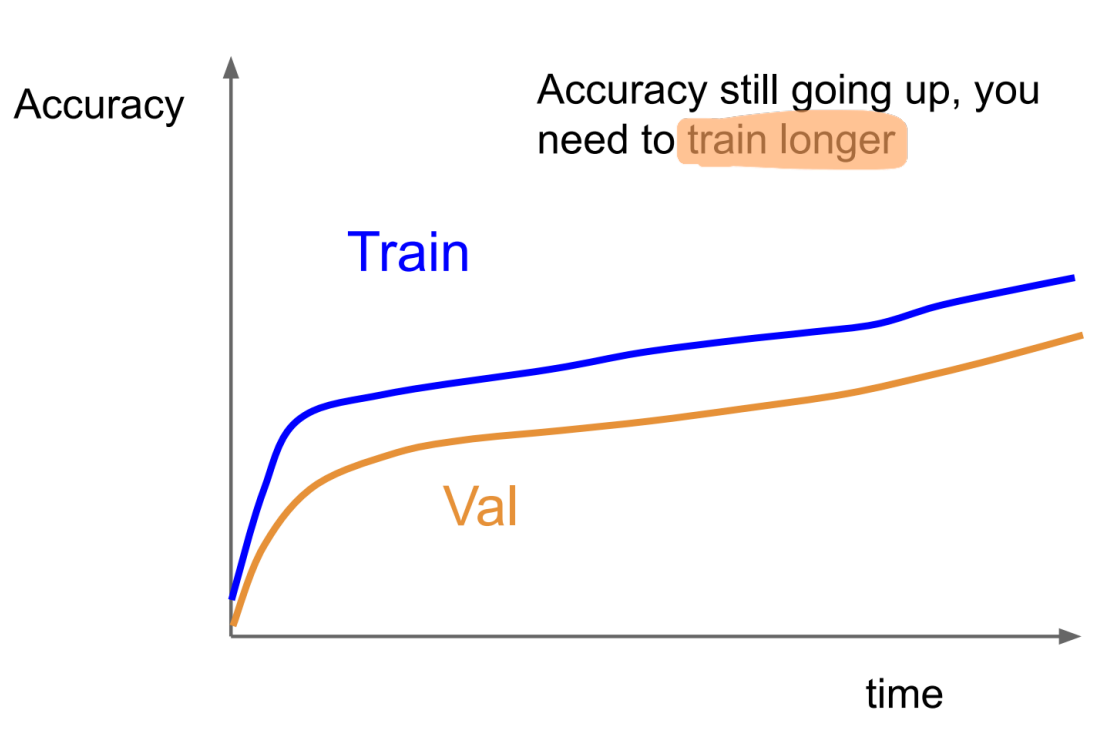
Accuracy가 아직 수렴하지 않고 계속 오르고 있다.
좀 더 많은 epoch동안 학습시켜 성능을 향상시켜야 한다.
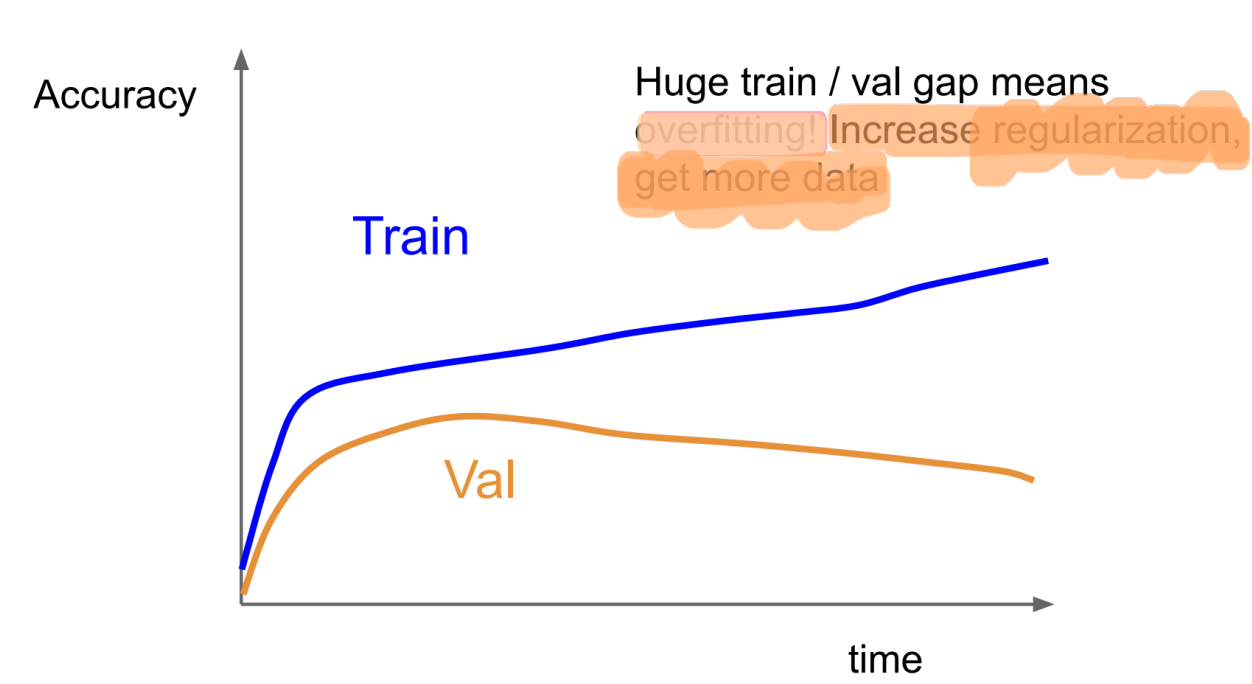
Training accuracy는 계속해서 오르나 validation accuracy가 증가하다 갑자기 감소하는 패턴은 전형적인 Overfitting이다.
이 때는 데이터 양을 늘리거나 규제를 사용해 모델의 복잡도를 줄여야 한다.
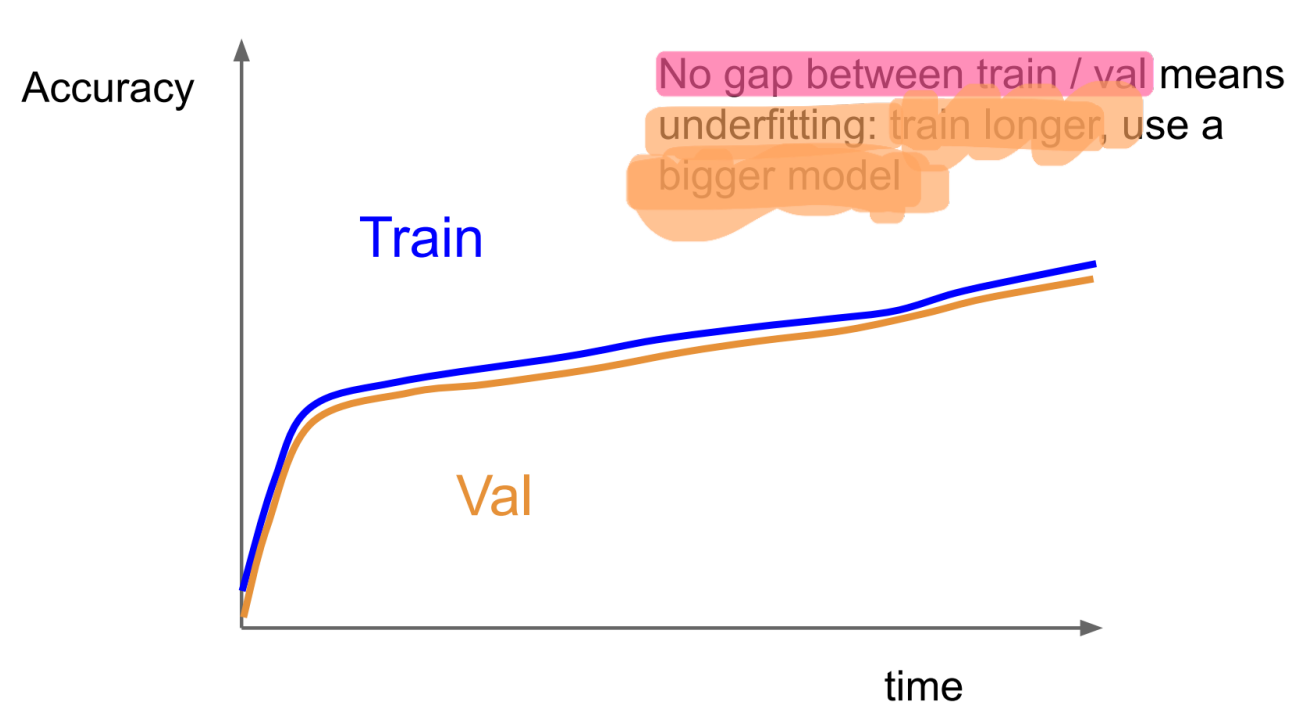
Train/Val Accuracy간 차이가 없다.
정상적으로 학습이 된다면 Training Accuracy가 Validation Accuracy보다 살짝 높아야 한다.
'학습' 자체가 잘 되고 있지 않을 가능성이 있다.
'Data Science > ML | DL' 카테고리의 다른 글
| Generative Model: Perceptual Loss와 Style Loss (1) | 2023.10.12 |
|---|---|
| MLE와 Bayesian Optimization (0) | 2023.08.10 |
| Optimization: Gradient Descent를 넘어서 (0) | 2023.03.06 |
| Training Technique: Regularization(규제) (0) | 2023.03.06 |
| Training Technique: Data Pre-processing, Weight Initialization, Feature Normalization (0) | 2023.03.05 |