https://github.com/isl-org/ZoeDepth
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
※ SIDE
Single-Image Depth Estimation
하나의 RGB 이미지가 주어졌을 때 그것의 dense depth map을 구하는 task
※ Depth Estimation
말 그대로 이미지로부터 Depth를 Estimate하는 것.
각 픽셀별로 depth 값이 얼마인지 예측하는 것이 목표, per-pixel regression이라고 생각하면 됨.
최근 해당 문제를 depth value 가 어떻게 분포되어 있는지를 classification-regression problem으로 reformulate하려는 시도가 이루어지는 중. (discretizing, bins,,,)
⇒ MDE와 RDE를 결합한 two-stage framework!
😶기존 모델의 특성과 한계점
SIDE task의 대표적인 two branches: MDE, RDE
✨MDE(Metric Depth Estimation)
- 절대적인 physical unit으로서의 depth를 구하는 것이 목적
- 많은 downstream utility에 실용적으로 적용 가능
- multiple dataset에 걸쳐 SIDE하는 것이 overfitting을 일으켜 generalize 측면에서 좋지 못함 ( (특히, 데이터셋 collection에 depth scale에 있어 큰 차이가 있는 이미지가 섞여있을 때 ; e.g. indoor/outdoor)
✨RDE(Relative Depth Estimation)
- scale을 factor out시킴으로써 multiple type의 environments의 다양한 depth scale에 대응
- 이미지 프레임에 걸쳐 연관된 것들끼리만 per pixel depth prediction이 일관적, scale factor는 unknown한 결과 (상대적인 depth를 계산한다고 이해할 것)
- 다양한 scale의 depth set의 dataset에 훈련이 가능하도록 함 ⇒ enabling generability across domain
- predicted depth에 metric 의미가 없어 application이 제한적임
⇒ 두 가지 method를 결합해 two-stage framework
⇒ LocalBins를 개선한 구조 제안
😶훈련과 인퍼런스 과정

✨Training Step1: Relative Depth Estimation (with MiDaS)
- Encoder-Decoder 구조(여기서는 MiDaS)를 사용해 훈련하여 Relative Depth 계산훈련
- good generalization을 목표로 large variety of dataset을 pretrain
✨Training Step2: Fine Tuning (with Metric Bins Module)
- step1에서 사용한 encoder-decoder architecture에 **“metric heads”**를 붙여서 metric depth 계산 훈련
- 서로 다른 depth domain이 있다고 쳤을 때, Domain Specific Head가 있다고 이해할 것
- dataset에 대해서 fine tuning
✨Inference State
- 이미지를 모델에 넣으면 모델 encoder classifier에서 적절한 metric head로 route됨
- pixel당 single depth value를 output으로 내지 않고 a set of depth values를 결과로 냄
- ‘Attractor’를 사용해 decoder의 각 layer에서 values의 estimation을 transform하도록 하는 것.
😶구조
✨MiDaS (Pre-Training)
- relative depth prediction을 위해 제안된 training 기법 (2020)
- scale과 shift에 invariant한 loss를 사용 ⇒ 다수의 dataset이 있다면 multi-task loss가 적용됨
- Base Model로 DPT encoder-decoder architecture를 사용, encoder 부분을 transformer-based model로 대체
- pre-training의 용도
✨Metric Bins Module
- bin center 계산 모듈
- LocalBins 구조에 영감받아 improve한 구조를 제안
- LocalBins
-- SIDE문제의 discretizing 방식으로 제안된 구조중 하나(2022년)
ㄴ-- encoder-decoder결과인 multi-scale feature를 input으로 하는 module을 붙여 모든 pixel마다 bin center를 예측
ㄴ-- 예측한 bin center의 확률기반 weighted linear combination으로 최종 depth를 계산
- input: MiDaS Decoder에서 온 multi-scale feature (fig 2 참고, 분수의 의미) output: bin center (추후 metric depth prediction에 사용될 것)
- bottleneck에서 ‘모든’ bin center를 예측
- 기존과 다른 점은 bottle neck(encoder-decoder를 잇는 부분, fig2 참고)에서 작은 수의 bin에서 시작해서 split하는게 아니라 처음부터 모든 bin center를 예측한다는 점 (이후 Attractor를 위해).
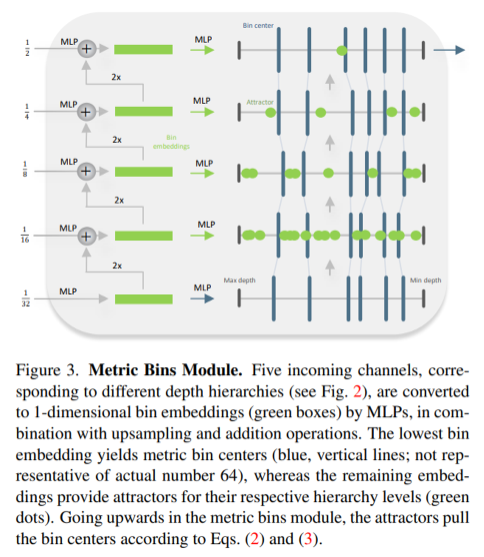
✨Attractor Instead of Split (Fine Tuning, Attractor Layer)
- LocalBins에서 적용하는 multi-scale refinement of the bins by splitting them대신, multi-scale refinement of the bins by adjusting them; moving left or right on the depth interval을 적용
- l 번째 decoder layer에서 MLP가 attractor points들을 predict
- attractor들이 bin을 ‘attract’하여 조정
⇒ 기존 splitting 방식은 dilative한 반면, 해당 방식은 contracting process
⇒ local constraint 없이 attractor들이 adjust되는 효과
✨Log-binomial Instead of Softmax

- final depth prediction 과정
- bin center를 확률 score를 기준으로 weighted linear combination
- 기존 LocalBins는 bin centers들에서 probability distribution을 예측하는 데 softmax를 사용
ㄴ-- 그 이유는 discrete classification analogy를 위해서.
ㄴ-- bins가 내재적으로 정렬되어있어, softmax가 ordering-aware prediction을 할 가능성이 존재
- unordered prediction을 위해 이항분포(Binomial Distribution) 사용
ㄴ-- t는 resulting distribution을 control
ㄴ-- q는 mode의 placement를 control
ㄴ-- practical 목적으로 log(p)를 취함
ㄴ-- numerical stability를 위해서 log(p)에 softmax를 취해 normalization (to preserve unimodality of the logits)
✨Loss
- LocalBins과 동일하게, pixel-level supervision에는 scale-invariant log loss를 사용
- LocalBins과 다르게, 성능향상대비 high memory requirement를 이유로 chamfer loss는 사용하지 않음
😶실험결과, 성능비교
depth pre-training(step1)없이 metric bins module(step2)만 적용했을 때도 indoor depth estimation은 SOTA모델(NeWCRFs)을 뛰어넘음을 보임
step1을 함께 적용했을 때는 SOTA보다 21% 정도의 improvement를 보임
zero-shot capability 증명
😶Contribution
여러 Depth 도메인에서의 유연한 적용
- indoor, outdoor domain에 따라서 depth 범위 특성이 천차만별
- 어떤 카메라(각도)로 찍었는지 뿐 아니라 overall scale의 variation까지 이해해야 함
⇒ 서로 다른 Metric Heads가 scene-type Expert로서 작용하는 효과!
two stage training으로 relative depth & metric depth 모두 고려한 계산
- first stage에서 relative depth를 사용해 모델 pretrain
- second stage에서 domain specific head를 사용해 metric depth fine tune
⇒ relative depth, metric depth 각각에서 오는 장점을 모두 가져감