기존 방식에 positional encoding을 추가하여 decoder에서 Normalizing Flow를 학습함.
이전 모델의 문제점😶
Real Time System에 맞지 않는 클러스터링 기반 모델들
SPADE와 같은 모델은 KNN기반의 모델들. Clustering에 기반한 이런 모델들은 high-dimensional data에 대해서 test time이 긴 것이 단점. 이는 Real Time System에 적합하지 않은 모델임.
(PaDiM은 이런 문제 해결을 위해 Mahalanobis Matrix를 만들었음.(논문에서도 해당 개념을 차용하여 Flow를 만들어냄을 확인가능) 이후 PatchCore에서도 Sampling 등으로 testing시간을 줄이려 하는 시도가 있었음.)
Parallel Convolutional Method가 필요하다고 논문에서 언급.
Generative Model(Reconstruction Based)의 단점
pixel 또는 patch 단위의 reconstruction error를 계산, 이를 anomaly score로 활용. 정확한 exact data likelihood를 알 수 없다는 점이 단점.
Localization에 적합하지 않은 모델
(DifferNet)NF기반. localization에는 적합하지 않은데(localization이 수치로 detection이 안됨. patch 단위로 쪼개지는 않지만, gradient map을 그려서 눈으로 확인해야 함.), 이 개념을 extend 하여 localization에 적합하도록 만듦. (conditional normalizing flow)
강조포인트
pixel-level detection에 적합
Real Time System에 맞는 inference 속도
Theoretical Background😶
1. Mahalanobis Distance
(PadiM에서 inference time을 줄이기 위해 쓴 방식.)
CNN classifier의 confidence score로 사용되는 method임.
특정한 feature vector z와, multivariate gaussian distribution(MVG)과의 거리라는 점에서 Anomaly Detection에서 사용됨.

z가 MVG의 분포와 많이 떨어져있다면 거리가 크게 나올 것.
이러한 Mahalanobis distance의 개념은 image-level detection task에서 효과적임이 드러남.
2. Flow Framework
Normalizing Flow의 개념을 사용.
임의의 z에 대한 likelihood는 아래와 같이 계산됨.

여기서 u는 bijective한 flow 함수f(inverse)를 통해 z에서부터 도달한 standard MVG U(z0이라고 이해할 것)의 샘플.
마지막 항의 행렬 J는 그 invertible한 모델의 야코비행렬.
위 log likelihood를 maximize하는 방향으로 stochastic gradient descent함.
loss function은 아래와 같이 정의될 수 있을 것.

model prediction과 target density와의 likelihood 차이의 기댓값이 곧 loss임.
이를 위의 Mahalanobis Distance 공식을 이용해 치환하면 아래와 같이 나타낼 수 있음.
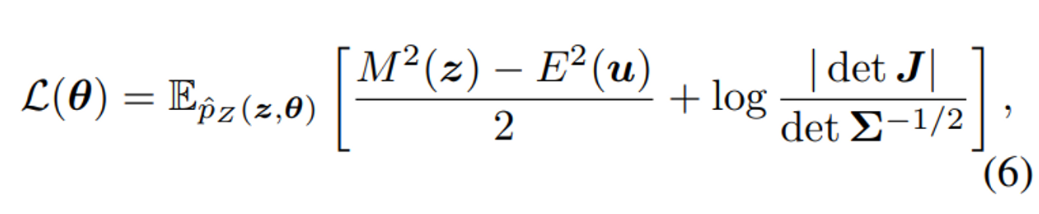
이렇게 Normalizing Flow를 쓰게 되면 어떤 임의의 z의 likelihood도 exact하게 구하는 것이 가능함.
Mahalanobis Distance는 그 분포가 MVG임에만 한정적이니까. (가정이 필요)
논문에서는 여기에 더해 **‘conditional normalizing flow’**를 사용해, more compact하면서도 fully-convolutional parallel architecture임을 강조.
구조😶

1. Encoder for Feature Extraction
multi-scale feature pyramid pooling 형태의 feature extraction과정.
encoder h(λ)를 사용하여 다양한 semantic level에서의 feature z들을 추출함(그림 참고)
“Encoder maps images patches x into a feature vectors z that contain relevant semantic information about their content”
모델은 ImageNet데이터로 pretrained된 CNN 모델을 사용.
k개의 pooling layer 각각에서 feature vector를 extract해서, 총 k개의 feature vector를 얻어내게 됨
layer가 깊어지면서 receptive field가 넓어지므로 local부터 global patch information까지 얻을 수 있음.
(PaDiM에서는 인코딩 단계에서 extract한 feature vector들을 resizing시켜 concat해주는데, CFLOW는 이후 디코딩 한 후 aggregate해줌. 따라서 extract한 feature vector들이 그대로 디코더 각각으로 넘어감.)
2. Decoder for Likelihood Estimation(핵심)
extract한 feature vector들의 log-likelihood estimation을 위해서, normalizing flow에 넣는 과정임.
특징은, decoder에 feature input외에 condition vector를 함께 넣어준다는 것. (conditional normalizing flow!)
여기서 conditional vector는 그림에서 c를 의미, positional encoding을 사용해 얻어냄.
Positional Encoding에 대한 이해는 아래 블로그를 참고함.
(sin함수 cos함수를 활용해 vector의 고유한 위치를 연속적인 함수 형태로 인코딩해내는 기법이라는 정도로만 이해함.)
정리하면, 총 k개의 feature vector와, k개의 conditional vector를 k개의 decoder에 각각 넣어 normal distribution 형태로 만들도록 하는 f(inverse)를 학습하는 것. 학습은 보통의 normalizing flow 방식과 동일함.

loss function. z의 likelihood를 최대화하도록=gaussian distribution형태가 되도록=위 loss를 최소화하도록 학습.
k개 scale의 decoder를 모두 훈련한 후에는 loglikelihood를 probability 형태로 변환하고 0~1범위로 normalize해줌.
각각을 이미지 크기와 동일하게 업샘플링, 모두를 aggregate해주면 그것이 anomaly score map이 됨.(segmentation)
장점
- Real Time System에 적합한 만큼의 가벼움, 빠름decoder function을 학습시키고, inference할 때 단순히 data의 loglikelihood를 계산하는 것으로 끝. experiment 결과 보면 시간이 많이 단축됨을 알 수 있음.
- Representation Based Model과 비교하여, Memory Bank를 저장할 공간이 필요 없고(SPADE) clustering과정이 필요 없어 inference 시간을 단축. (PaDiM도 Mahalanobis Matrix 저장할 공간이 필요함)
- Exact Likelihood를 계산
- Reconstruction Based model과 달리 Normalizing Flow를 사용해 likelihood를 직접 계산.
- multi-scale feature map을 사용해 localization에 적합.
예상되는 한계점/언급이 안되어 있는 부분
align 안되어있으면 어떻게 되려나.
질문
- 그래서, positional encoding을 과정에 추가해주는 것에서 오는 이점이 무엇인가? localization?
- 디코더 마지막 단계에서 aggregate하는데, 그 과정이 이해되지 않음.
포인트
positional encoding을 통한 conditional normalizing flow.
기존 방식에 positional encoding을 추가하여 decoder에서 Normalizing Flow를 학습함.