NLP를 위한 딥모델들
RNN, TextCNN, Transformer, BERT(Transformer encoder), GPT(Transformer decoder)
RNN😶

Seq2seq 형태의 RNN 모델들은 멀리 떨어진 단어들의 모델링이 어려움.
순차적으로 진행되기 때문에 input이 길어질수록 속도가 느려짐. (병렬화가 힘듦.)
TextCNN😶
1차원(text)을 2차원(이미지) 형태인 단어 임베딩으로 바꿔서 표현한다면 CNN으로 학습을 할 수 있다는 아이디에서 착안.

속도에 있어서는 RNN보다 빠른 계산이 가능.
하지만 RNN보다, 멀리 떨어진 단어들에 대한 모델링이 힘듦.
성능은 나쁘지 않음.
Transformer (Attention is All You Need)😶
https://arxiv.org/abs/1706.03762
RNN, CNN구조 없이 오직 Attention만으로 단어 의미를 문맥에 맞게 잘 표현이 가능
BERT, GPT의 기반
병렬화 가능이 장점.
✔️문제
Seq2Seq(순차 입력에 대해 순차 출력을 반환. 기계번역, 질의응답 등)
✔️Inference
입력이 je suis etudiant이면, 출력으로 I am a student를 뱉는 큰 블랙박스.
블랙박스는 encoder와 decoder로 구성.
[Encoder]
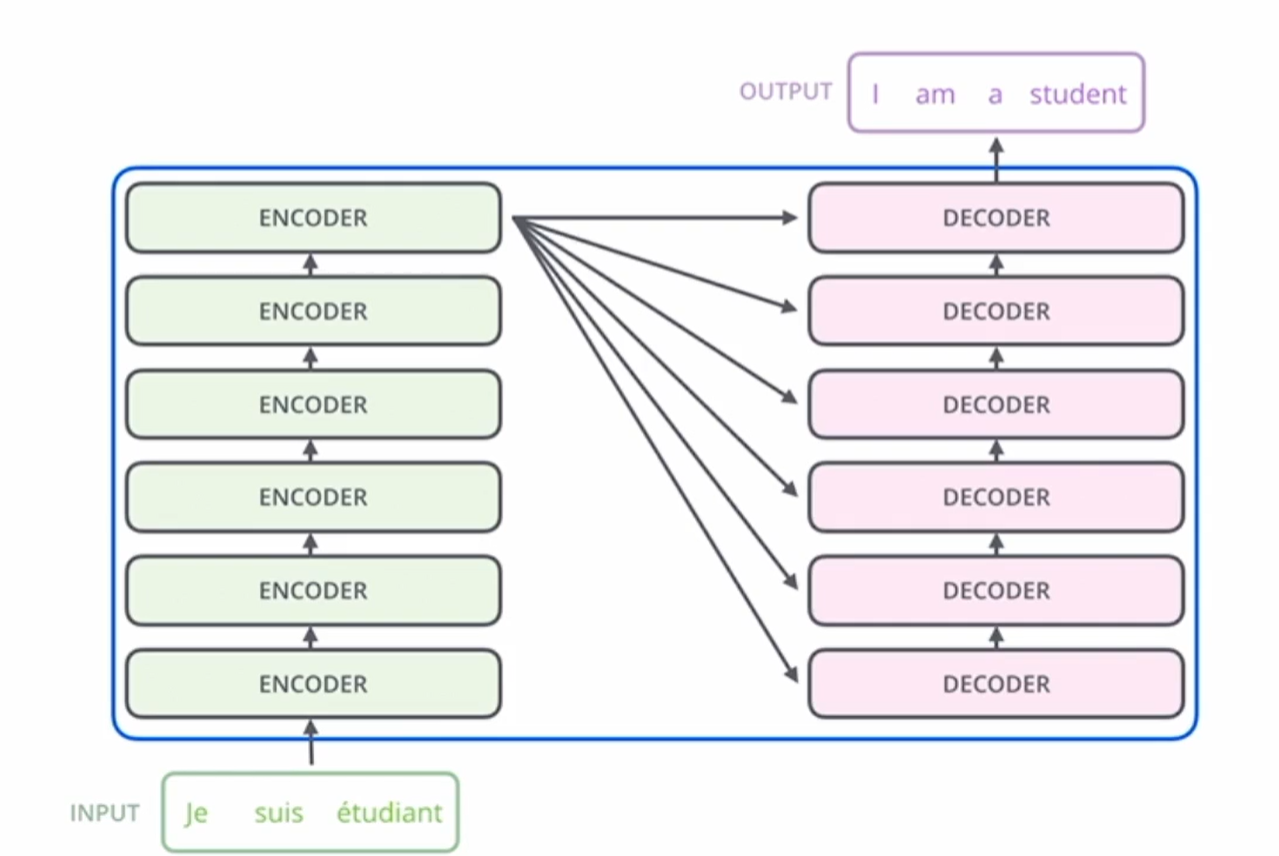
인코더는 동일한 형태의 인코더들이 쌓여있는 형태, 단 각 인코더들이 파라미터를 공유하지는 않음.
디코더도 마찬가지로 동일한 형태의 디코더들이 쌓여있지만 파라미터가 공유되지는 않음.

인코딩 단계에서 단어 임베딩은 self-attention을 통과하면서, 그 주변 단어를 고려한 문맥적인 의미 z로 변환됨.
이후 feed forward NN층을 통과. 이때는 주변 단어와 관계없이 단어 개별적으로 계산되므로 병렬연산이 가능함.

feed forward 층을 통과한 후에는 다음 인코더층으로 전달.
* Self Attention
1. 모든 입력 단어들인 X를 사용해 Query, Key, Value를 만든다.
attention은 쿼리와 키의 유사도를 내적으로 구하고, 거기에 value를 곱하는 형태.
self attention은 모든 입력 단어들 X를 사용해서 세 요소 모두를 만든다는 점이 일반적인 attention과 차이.
 |
 |
2. Q, K, V를 각각 균일하게 나눈다. 나눈 벡터의 일부분을 head라고 한다.
3. head를 이용해 attention을 계산한다.
쿼리와 키를 내적한 값에 소프트맥스를 적용해 각 단어끼리의 중요도를 얻어냄.
얻어낸 중요도에 value를 곱하면 attention 계산이 완료.
+) 벡터를 나누어서 계산하면(2번 과정) 한 번에 여러 개의 특징을 추출할 수 있는 멀티헤드 셀프 어텐션이 됨.
**self attention을 함으로써 얻을 수 있는 이점

자기 자신에서 온 쿼리, 키를 내적해 유사도를 구하고 어텐션을 만들어 냄으로써,
단어가 문장 안에서 어떤 의미인지 알 수 있게 됨.
예시문장: '그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다.’
‘그것’이 의미하는 것이 street인지, animal인지 컴퓨터는 알 수 없음.
하지만 self attention을 사용하면 it과 animal 간의 attention결과가 높게 나올 것이기 때문에
animal을 의미하는 것을 알 수 있음.
bidirectional 측면에서도 강점이 있음.
앞단어들 뿐만아니라 뒤의 단어들도 함께 고려하여 학습이 가능함.
[Decoder]
인코더 마지막 층에서 얻은 z와 + 처음부터 직전 단어 를 input으로 하여 그 다음 단어를 생성.
디코더 입력의 셀프 어텐션을 구하는 단계.

단, 현재 시점 이후의 단어를 미리 알 수 없으므로, 현재 시점 이후의 단어 임베딩에는 매우 큰 음의 실수를 넣어서,
소프트맥스에 넣었을 때 확률이 거의 0이 나오도록 함.(마스킹.)
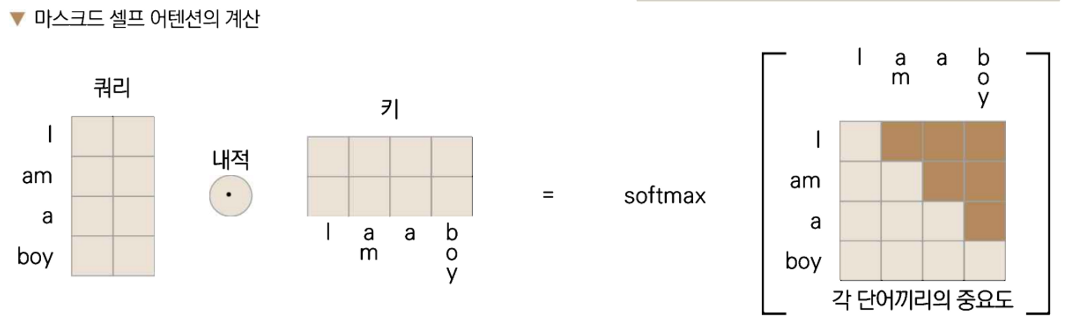
(현시점 기준 과거의 단어만 고려하기 위해서.)
✔️Loss Function
cross entropy.
단어별 softmax 형태와 정답형태간의 에러를 cross entropy로 계산.
복잡한 형태의 모델이 결국 loss 최소화 문제로 귀결.
BERT😶
Transformer의 인코더만 따서 만든 모델
Transfer learning으로 적은 양의 데이터로 양질의 모델을 학습하는 방식
*Transfer Learning
원래의 모델 파라미터를 가져오고, 거기서 적은 데이터를 추가해서 모델 파라미터를 목적에 맞게 좀 더 튜닝하는 방식.
✔️Inference

스팸메일 분류모델이라고 치면,
BERT로 Pretraining한 후 Classifier로 Spam메일 여부를 판단하는 과정으로 inference를 진행.
Pretraining

Transformer의 인코더부분만 떼어온 형태.
단어 임베딩을 문맥 벡터로 바꿈.
문장 일부를 마스킹하여 훈련하기도 함.
Fine Tuning
Classifier. Feed Forward Neural Network형태.
+) BERT pretraining을 통해 문맥화된 임베딩 자체가 다른 모델의 input으로 활용되기도 함.
'Data Science > ML | DL' 카테고리의 다른 글
| Training Technique: Data Pre-processing, Weight Initialization, Feature Normalization (0) | 2023.03.05 |
|---|---|
| Backpropagation (0) | 2023.03.05 |
| Neural Network의 구조와 Non-Linear Activation Function (0) | 2022.09.04 |
| Anomaly Detection Model 공부를 위한 Normalizing Flow 정리 (0) | 2022.08.30 |
| Optimization: Random Search부터 Gradient Descent까지 (0) | 2022.08.21 |